In my continuing quest to be a jack of some CS-related trades and a master of absolutely zilch, I've decided to learn about some buzzword-y tech for deployment and packaging.
First of all, I wanted to look into Continuous Integration. I chose Travis for three reasons:
- I'd heard it recommended everywhere for its easy integration with Github;
- I didn't want to set up and deploy a Jenkins server, that sounded like a lot of work; and
- I had Travis for private repositories free with the Github Education pack:
To set it up, I created an account at travis-ci.com. The ".com" is important here - this site contains private repositories, while travis-ci.org contains those publicly visible.
I activated the repository I wanted to test from my Accounts...

...and added a .travis.yml file to the repository's root.
My .travis.yml was relatively simple to start with: no deployment options, just running the unittests.
language: python
python:
- "3.5"
install: pip install -r requirements.txt
script: python -m unittest
(N.B. running python -m unittest with no options is equivalent to running it with the discover option: it'll search each subdirectory for unittest.TestCase and run everything it finds.)
So we have continuous integration. But what about deployment?
I did manage to make TravisCI deploy to both Amazon S3 and Heroku if the master branch built successfully, but unfortunately I don't have the .travis.yml file I used. For what it's worth: I didn't run into any significant problems using the instructions and examples from the deployment documentation.
I decided to try out Docker containers -- they were in the realm of "buzzwords I've heard and vaguely recognise", so I wanted to solidify my knowledge.
It turns out, Docker is absolute black magic. The idea is: you write a script to build a virtual machine and run your app, and it works everywhere. Any OS, any hardware. It's magic.
I wrote a toy Python/Flask app called "fruits-api", which retuned a random fruit in JSON format. Possibly the simplest RESTful API you could imagine, but that wasn't the point: I needed to see if Docker would handle installing all the Python requirements -- and indeed, all the system packages -- needed to deploy a web server.
To add some more complexity, I wanted this to scale for production, so I definitely wasn't going to run the inbuilt development server. I decided to use Gunicorn to serve the application to the localhost, and Nginx as a reverse proxy listening externally on port 80.
I familiarized myself with Docker by watching a 3h talk by Jérôme Petazzoni. Or, at least, more than half of it. I have a pretty short attention span.
After a whole LOT of screwing around with containers and discovering some nifty ways to speed up docker builds, I got something building. The structure looked like this:
.
├── Dockerfile
├── README.md
├── ops
│ ├── nginx.conf
│ └── requirements.txt
└── src
├── debug.py
└── fruitsapi
├── __init__.py
└── views.py
At the top level, we've got the Dockerfile, a Readme, and two folders: "ops" and "src". I'd love to be able to put the Dockerfile in "ops", but the Dockerfile location determines build context -- and you can't COPY anything from outside the build context.
The "ops" directory contains non-source code items for configuring the server. For this container, it's pretty simple: the nginx configuration file, and a requirements.txt to install our Python dependencies.
The nginx configuration file is pretty much copy-pasted, but with a different port and without the daemon off; directive: I'm not using supervisord or anything fancy, just using the nginx binary to start its service.
The Dockerfile has some comments of its own explaining what's going on. I've pasted it below:
I've also hosted the entire source for the container here:
https://github.com/bedekelly/fruits-api
It's on Docker Hub at bedekelly/fruits-api
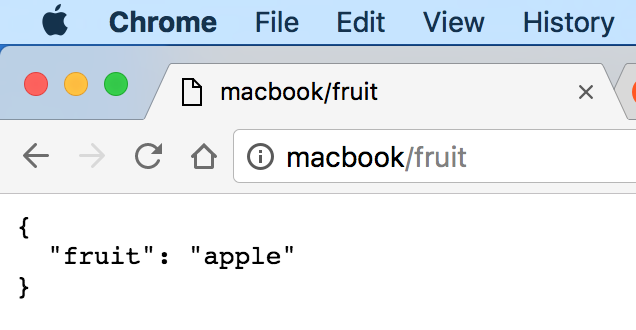
And here it is in action:
As for the actual deployment to production... turns out that's a bit more difficult than I imagined. I think I'll leave that for another post.
A few notes:
-
The virtualenvironment I'm using is outside the Docker build context. It doesn't have to be; that's just a relic of when I didn't have separate /src/ and /ops/ folders, was COPYing the current directory, and didn't want to include the hefty virtualenvironment. This would be solved by putting a
.dockerignorefile in the virtualenvironment, but I'd be excluding the virtualenvironment from the Git repository, so it's a change I'd have to make on every new machine. In the current configuration, the simplest thing to do would probably be to have the virtualenv folder at the same level as the /src/ and /ops/ folders, add it to the .gitignore, and only COPY things from the /src/ and /ops/ folders. But for now, it's the directory above, and it works just peachy! -
Before I decided to use nginx, I had a very confusing issue where gunicorn would be listening on port 127.0.0.1, and I wouldn't be able to connect to it from a browser. I knew the docker engine was in a virtual machine of sorts, so I was trying to configure it to use "bridge" networking to share the laptop's IP. Guess what? It was already using bridge networking. The problem turned out to be that gunicorn needed to listen on 0.0.0.0: the bridge network was working fine but gunicorn was seeing the requests coming through to what looked like an external IP, and just dropping everything. I got it working with gunicorn, then decided to add nginx. Nginx was on the same VM as gunicorn, so gunicorn could go back to listening on 127.0.0.1, while Nginx proxied the "outside" traffic to it locally. When running the Docker image, I have to map the "outside" port 80 to the internal port 80, which Nginx is listening on.
-
The
macbookname is an /etc/hosts entry to 127.0.0.1, that works just likelocalhost. I also havehere,home,meand a few others. It's kinda neat. -
Kitematic comes with the Docker Toolbox and is a very pretty GUI for managing running containers. It helped a bunch when I needed to debug the port-listening issue above without manually restarting containers each time.