Who needs servers anyway? I've been wanting to try out AWS Lambda and API Gateway for a while now, so I thought it'd be a neat idea to write a tiny, not-even-slightly-useful microservice. I'm calling it PaaS...
...Pluralization as a Service.
I'd also like to do a couple of things "right" -- I want to be able to version-control my code, rather than just uploading a zip, and I'd like to use Git to do so (instead of relying on Amazon's own versioning system for Lambda).
So, first things first: I'll set up the project infrastructure. Luckily for me, I won't need to deal with Virtual Private Cloud (VPC) configuration this early, as by default Lambda functions are placed in a VPC of their own anyway. Later on, when I explore integrating with other AWS offerings such as DynamoDB, I'll have to think more about the way my network is structured.
After navigating to Lambda from the console, I've clicked "Get Started", and skipped the Select Blueprint step -- I'd like to get familiar with as much manual configuration as possible.
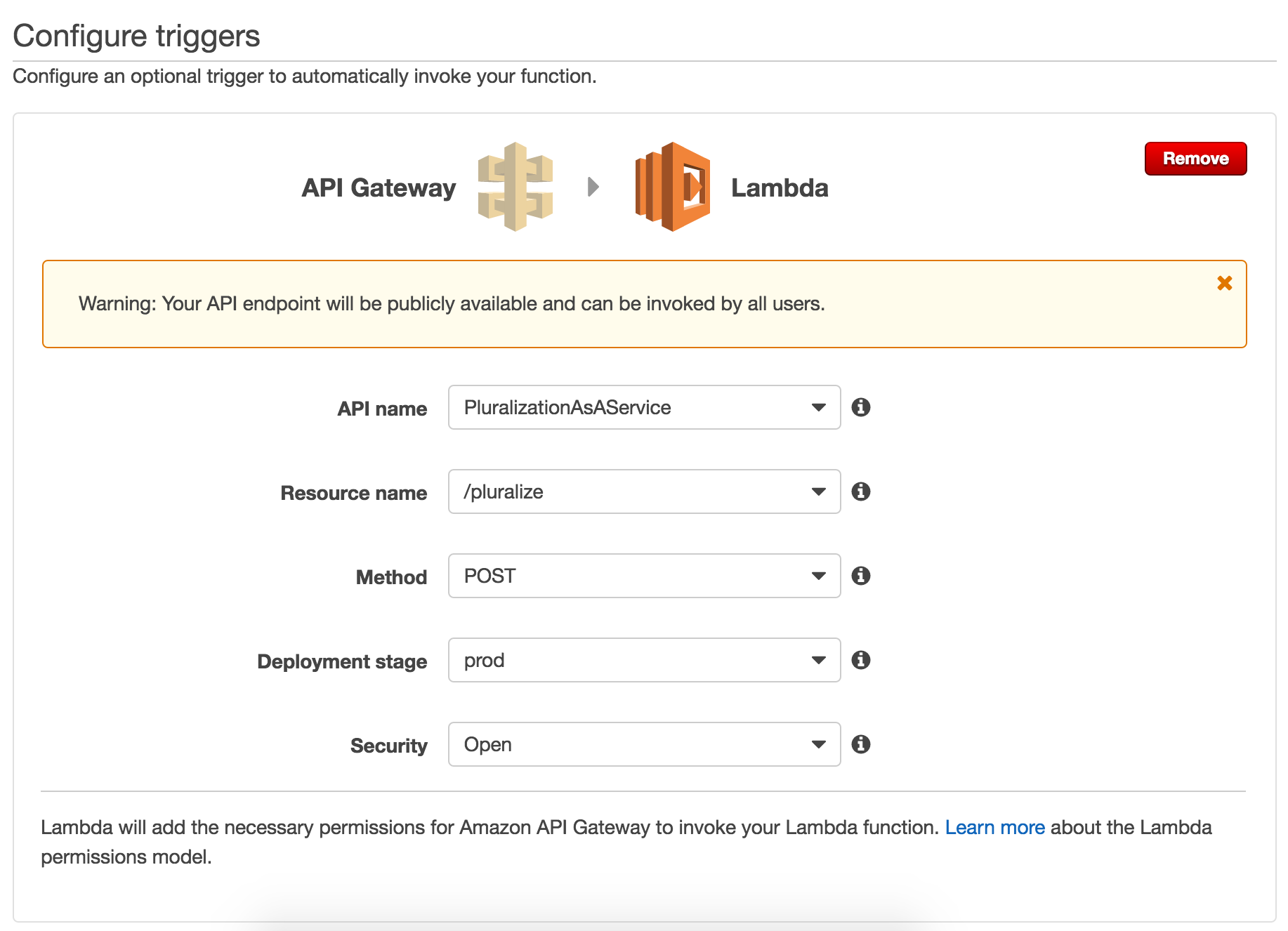
In the Configure Triggers menu, I've elected to make this function open and accessible through API Gateway -- I don't want to deal with IAM quite yet, and besides, it's an important public service!
At the next stage, Configure Function, I realise I can't set up the Lambda function without having any code for it available.
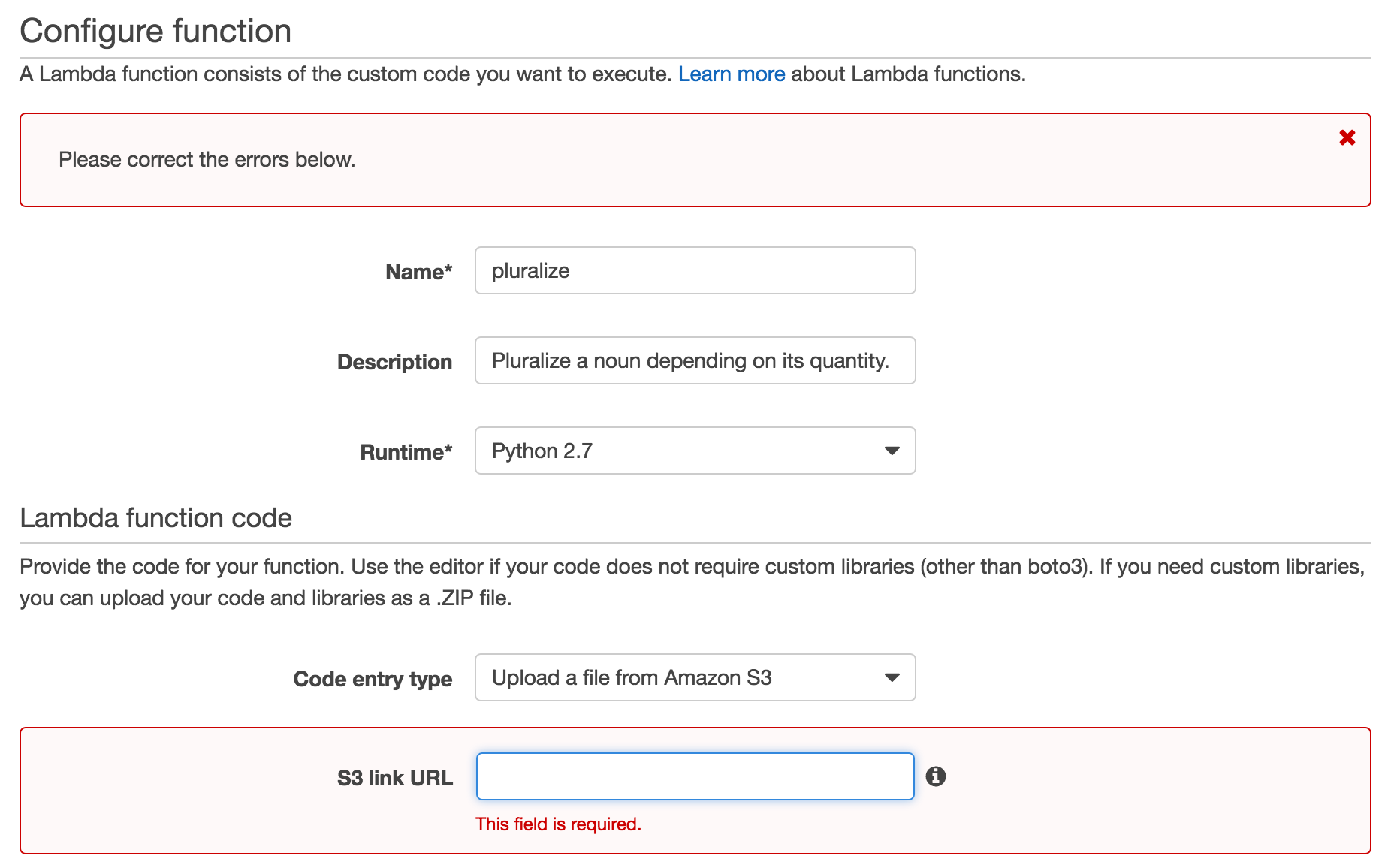
I'll leave this tab open, and work on the actual code itself.
After 20 minutes or so of work, I've got a simple repository with some tests for the business logic. I haven't tested the actual Lambda handler yet (and I'm far too lazy to read the docs) but I've put in some pprint statements which will hopefully show up in the Lambda log, telling me what format the event and context objects are given.
I'll be using Travis CI to run these tests automatically on each change to the Master branch, and when successful, deploy them to Amazon S3. Before I do that, however, I'll need to create an S3 bucket:
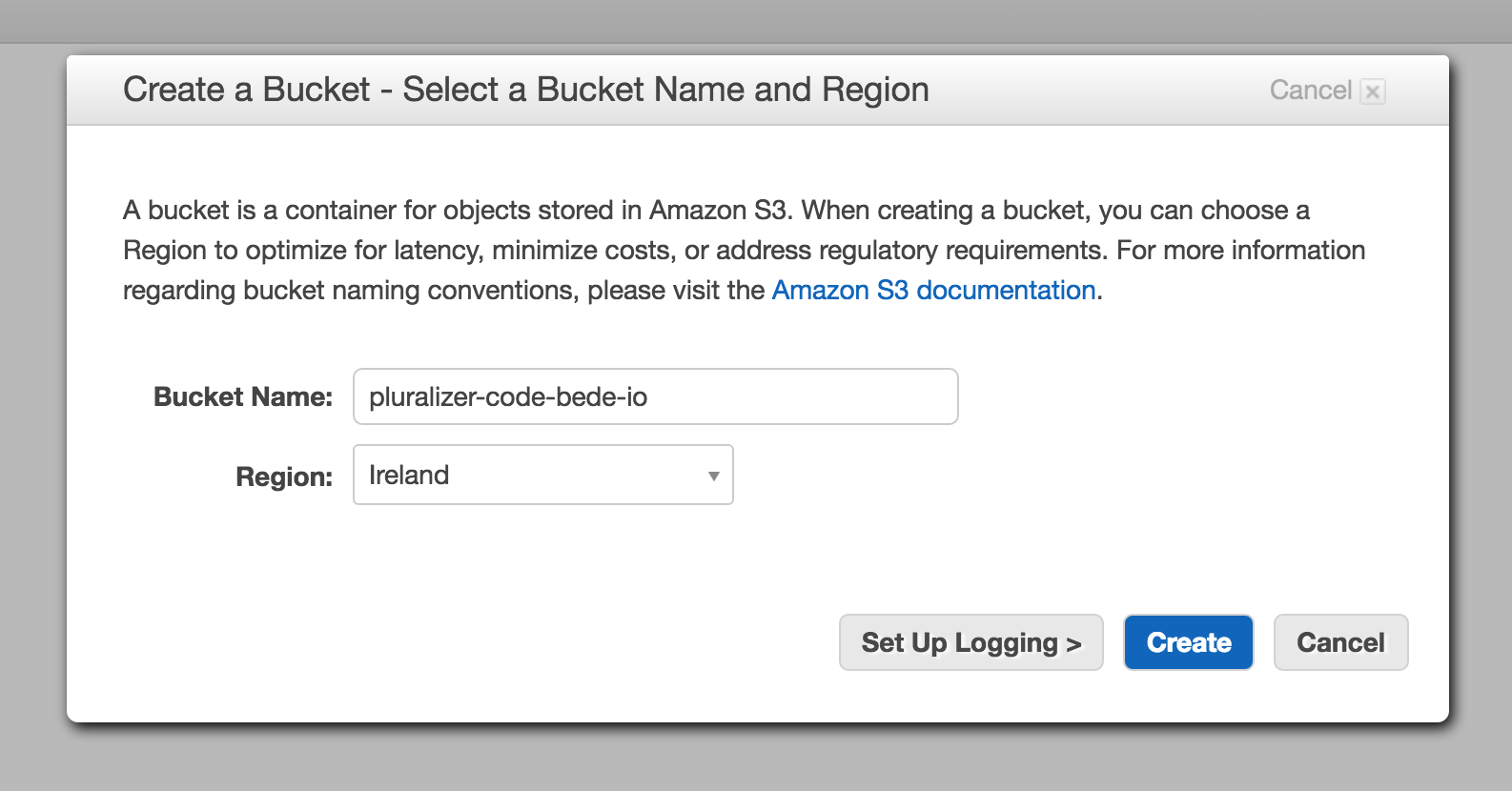
I'll also need an IAM user who has access to that bucket: I created one called pluralizer-travis-ci through the Console, and assigned it this inline policy:
{
"Statement": [
{
"Effect": "Allow",
"Action": "s3:ListAllMyBuckets",
"Resource": "arn:aws:s3:::*"
},
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::pluralizer-code-bede-io*"
]
}
]
}
(I slightly modified this from a policy I found online somewhere and now can't find the blog in order to credit them! Thanks anyway, anonymous stranger.)
In future, I'll be looking to create policies from the templates Amazon provides instead of starting from an inline JSON file.
I downloaded the ID and secret key for this IAM user, and put it in my .travis.yml file. Stupidly, I didn't actually encrypt it the first time around -- I'm EXTREMELY grateful I took the time to create a user with limited permissions instead of just pasting my root AWS credentials in as many tutorials seem to recommend.
At this point I push my code, and watch as Travis successfully installs, tests and deploys my code to the S3 bucket I specified.
It's at this point that I realise that Travis CI supports uploading directly to AWS Lambda, without having to touch S3 at all. To be continued...